Git Commits as Documentation (RAG-Powered Commit Search)
If you know me, you know that I love Git, and I believe if you use it right, it can be a powerful tool not only as a version control system but as a documentation tool. With Git, we basically document our code changes over time; It’s like writing a story ✍️. This is why I always try to write meaningful commit messages. As you know, a commit isn’t just a single line of text - it can be a paragraph or even a blog post by simply passing an extra -m when committing (you can also set core.editor to code to have a better editing experience: git config --global core.editor "code --wait"). The second part is called the body of the commit message. This is useful if you have extra information that you want captured in your commit, but you don’t want it in your commit message header. For example:
git commit -m "Add new feature" -m "This feature is useful because..."
Will produce the following commit message:
Add new feature
This feature is useful because...
The reason I love this approach is that I have this idea of Commit-Driven Development (and yeah, another X-DD 😄) where I write my commit first and then write the code to make the commit message true. This way, I have a clear goal in mind, and I know what I should do next. It’s kind of like TDD but in a more human-readable way. Most people follow this approach but they don’t use the body of the commit message; some others maybe write the body later once the task is done. In some projects the commit body contains valuable information, The following is a couple of commits messages from Nginx project:

I consider Commit-Driven Development a valuable approach. To me, it’s like a whiteboard where I can record my thoughts and ideas, and I believe many people share this perspective. This means there’s a wealth of knowledge embedded in the commit messages of a Git repository.
That’s where my idea comes in: creating a system to store commit messages in a SQLite database with a UI to search through them. By using Retrieval-Augmented Generation (RAG) and vector search, I can make the search results more relevant and meaningful. There might be ready-made solutions for this, But I want to try a new extension called sqlite-vec, a vector search SQLite extension that runs anywhere. Its latest version is written purely in C (which means that it can be run anywhere!)
Here’s an example of how I built a query endpoint that returns the 10 closest commits to a given prompt.
const query = async () => {
try {
// Some code
const prompt = "Where has math been used in this project?";
const promptEmbedding = await embeddingService.getEmbedding(prompt);
const result = sqlite
.prepare(
`
select * from commits where id in (
select commit_id from commits_vec where embedding match '${JSON.stringify(
prompt
)}' order by distance limit 2
)
and k = 10
`
)
.all();
const ragOutput = await embeddingService.generate(
`
Answer the following question using only the provided context. If the context doesn't contain enough information to answer the question, say so.
Context:
${JSON.stringify(
result.map((commit) => ({
id: commit.id,
hash: commit.hash,
message: commit.message,
author: commit.author,
dat: commit.date,
}))
)}
Question: ${prompt}
Instructions:
1. Only use information from the provided context
2. If the context doesn't contain enough information, say "I cannot answer this question based on the provided context"
3. Cite sources when possible using this format: "According to [commit id], [commit message]"
4. Be concise and direct
Answer:`
);
} catch (error) {
console.error("Query error:", error);
}
};
RAG is a technique to augment LLMs with specialised and mutable knowledge bases. The issue with the typical way of using LLMs is that we pass them a prompt and they generate responses based on their training data. But what if we want to pass specific information that isn’t in the training data? This is where RAG comes in - it makes prompts richer by first passing our query to a vector database to get the most relevant information. Then we pass this information as context as part of the prompt and have the LLM generate the response. This is a simplified version of the workflow I have for the project:
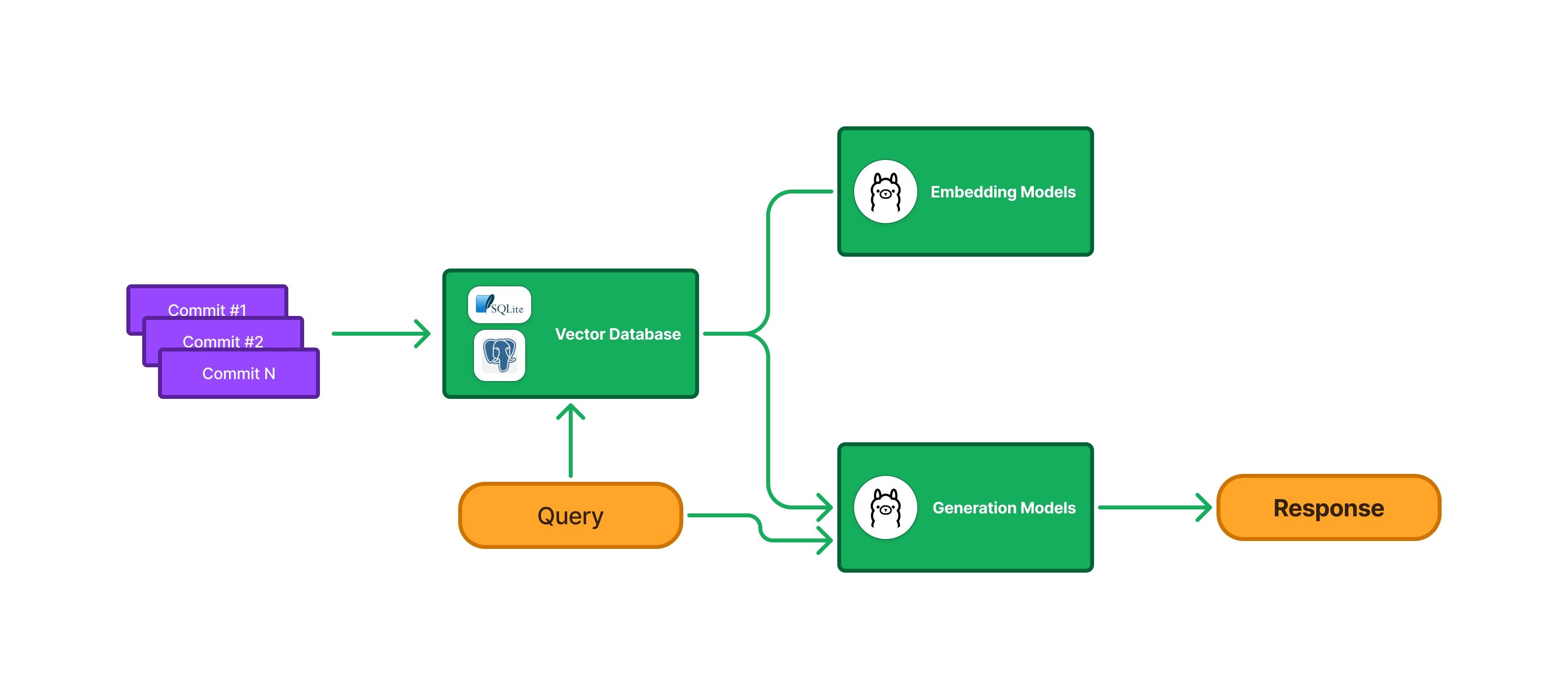
Note: For updating the vector database automatically, we can leverage Git hooks to post commit data to our backend.
Here’s an example using commits from the Svelte project:
{
"prompt": "Where has math been used in this project?",
"response": "According to [id:9555], Rich Harris mentioned \"computed values\" in a commit message, implying the use of mathematical calculations.\n\nAdditionally, according to [id:3064], Rich Harris also used \"Math.trunc\" (a function that truncates towards zero), indicating the use of mathematics for replacement purposes.\n\nAccording to [id:7d03b74576f3407f85ce1151dcdff01937d95708], Conduitry suggested using \"maps and sets\" instead of plain objects, but no specific mathematical concepts were mentioned."
}
I haven’t had time to build the UI yet, but I’ll probably continue working on it on another weekend when I have enough time and energy. For now, it’s just an API I built using Bun and Hono. For the UI, I’ll probably use Web Components as it’s my current focus (you should check out my /now page). I also used PostgreSQL as a vector database on a different branch using the pg-vec extension. It’s more stable than the SQLite version.